7.4 规整字符串提取数据的神器 — Python黑魔法手册 1.0.0 documentation (iswbm.com)
parse库,一个优雅而神奇的python库 - 知乎 (zhihu.com)
Intro
下面是 ovs 一个条流表,现在我需要收集提取一个虚拟机(网口)里有多少流量、多少包流经了这条流表。也就是每个 in_port 对应的 n_bytes、n_packets 的值 。
cookie=0x9816da8e872d717d, duration=298506.364s, table=0, n_packets=480, n_bytes=20160, priority=10,ip,in_port="tapbbdf080b-c2" actions=NORMAL
如果是你,你会怎么做呢?
先以逗号分隔开来,再以等号分隔取出值来?
你不妨可以尝试一下,写出来的代码应该和我想象的一样,没有一丝美感可言。
我来给你展示一下,我是怎么做的?
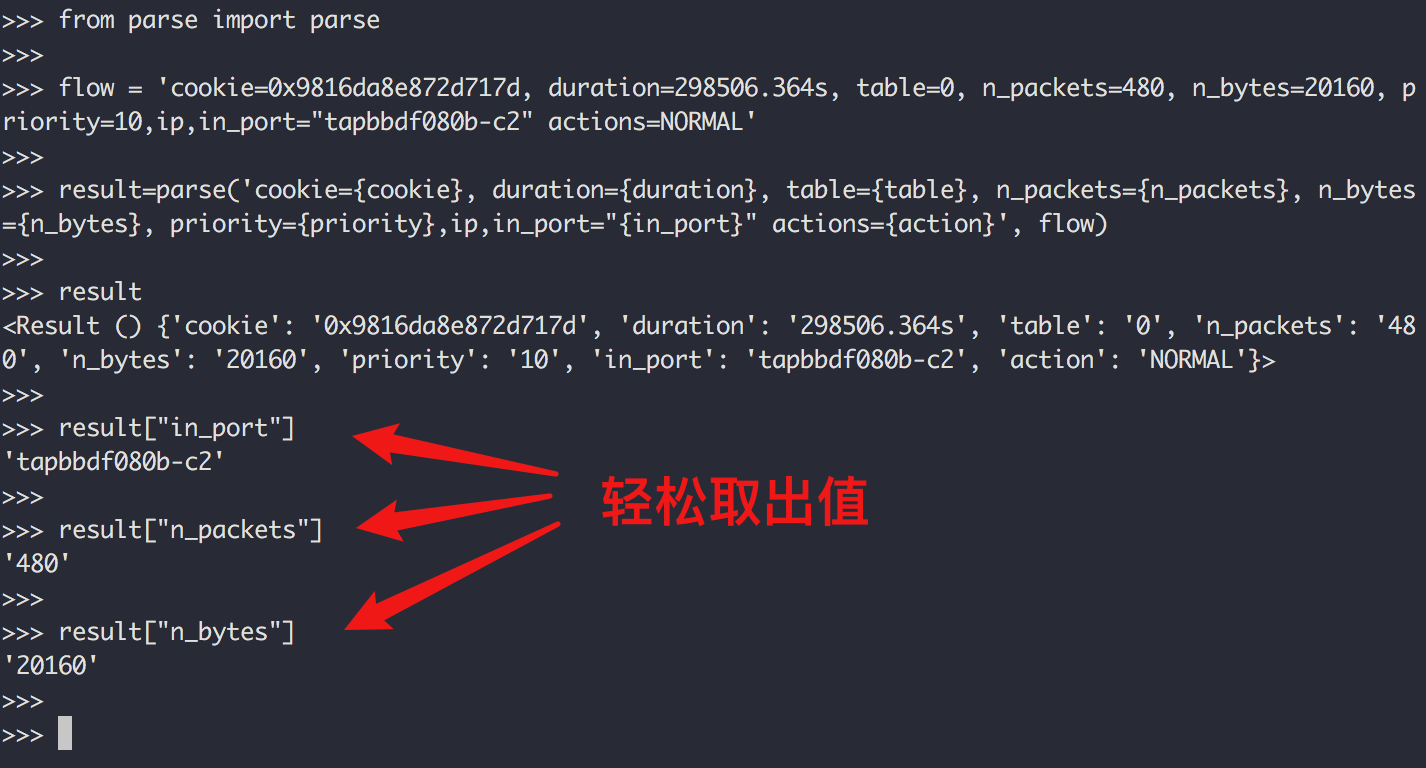
可以看到,我使用了一个叫做 parse 的第三方包,是需要自行安装的。
基本使用
parse 的结果只有两种:
- 没有匹配上,parse 的值为None
>>> parse("halo", "hello")is None
True
- 如果匹配上,parse 的值则 为 Result 实例
>>> parse("hello", "hello world")
>>> parse("hello", "hello")
<Result () {}>
可以看出来result有两种,一种是类字典的形式,一种是类list的形式。
如果你编写的解析规则,没有为字段定义字段名,也就是匿名字段, Result 将是一个 类似 list 的实例,演示如下:
>>>profile = parse("I am {}, {} years old, {}", "I am Jack, 27 years old, male")
>>>profile
<Result ('Jack', '27', 'male') {}>
>>>profile[0]
'Jack'
>>>profile[1]
'27'
>>>profile[2]
'male'
而如果你编写的解析规则,为字段定义了字段名, Result 将是一个 类似 字典 的实例,演示如下:
>>> profile = parse("I am {name}, {age} years old, {gender}", "I am Jack, 27 years old, male")
>>> profile
<Result () {'gender': 'male', 'age': '27', 'name': 'Jack'}>
>>> profile['name']
'Jack'
>>> profile['age']
'27'
>>> profile['gender']
'male'
重复利用 pattern
和使用 re 一样,parse 同样支持 pattern 复用。
>>>from parse import compile
>>>
>>>pattern = compile("I am {}, {} years old, {}")
>>>pattern.parse("I am Jack, 27 years old, male")
<Result ('Jack', '27', 'male') {}>
>>>
>>>pattern.parse("I am Tom, 26 years old, male")
<Result ('Tom', '26', 'male') {}>
[文章导入自 http://qzq-go.notion.site/585d6b98a28c41139009078483d8ded3 访问原文获取高清图片]
