2024.10.24
前言
最近师门在搞序列预测的东西,准备用LSTM来处理一批眼部追踪数据,因此需要学习一下,至少得弄出一个demo出来,看看LSTM好不好使。
本文阅读要求:至少对神经网络有一定的基础,反向传播,DNN这种都应该完全能理解掌握才行。本文不会展开讲公式,主要是应用为主,涉及到一些个人理解和具象化,如有偏颇请指正,感谢理解!
循环神经网络(Recurrent Neural Networks)
由于LSTM是RNN的一种变种,因此理解LSTM需要先了解RNN
人对一个问题的思考不会完全从头开始。比如你在阅读本片文章的时,你会根据之前理解过的信息来理解下面看到的文字。在理解当前文字的时候,你并不会忘记之前看过的文字,从头思考当前文字的含义。
传统的神经网络并不能做到这一点,这是在对这种序列信息(如语音)进行预测时的一个缺点。比如你想对电影中的每个片段去做事件分类,传统的神经网络是很难通过利用前面的事件信息来对后面事件进行分类。
循环神经网络(下面简称RNNs)可以通过不停的将信息循环操作,保证信息持续存在,从而解决上述问题。RNNs如下图所示
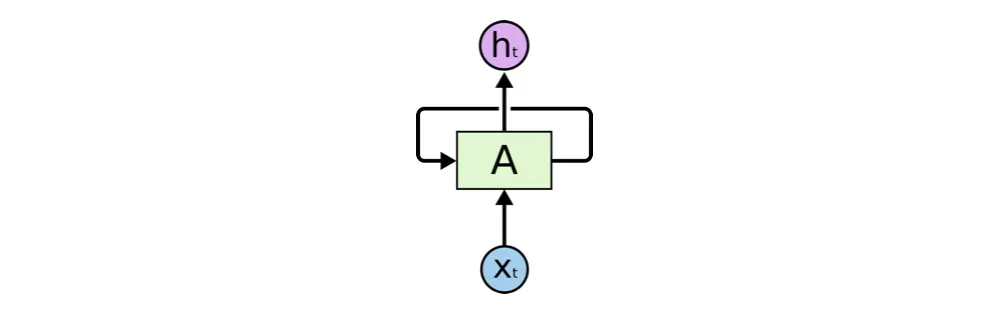
实际上我们经常看到的是展开了的情况,像是将同一个网络复制并连成一条线的结构,将自身提取的信息传递给下一个继承者,如下图所示:
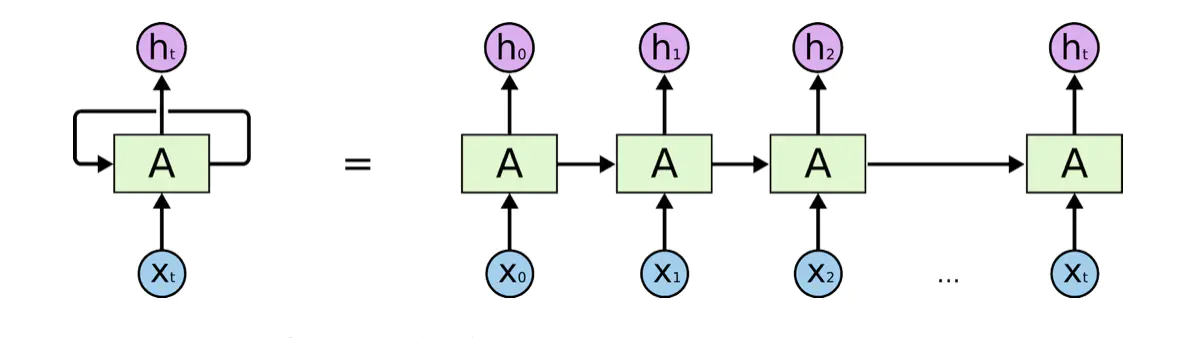
这里稍微展开讲一下,从直觉上来看,上述网络是注定处理不了长序列的。我们假定用RNN处理一段文字翻译工作,翻译【小明超级喜欢Python】。
网络会先处理第一个字,即【小】,然后是【明】,处理【明】的时候,上一次处理【小】的信息是被加权输入进网络的,我们设定这个上一个神经网络输入的信息权重为10%。那么当处理【超】这个字的时候,【小】的权重已经仅剩1%。也就算说,处理【超】的时候,神经网络看到的序列信息为:
最后,神经网络看到的序列信息:

以此类推,最后的神经网络得到的这个序列很可能会缺失信息,如下图:

像这样就可能完全缺失主语了,因此稍长序列是不宜用RNN处理的。
LSTM网络(Long Short Term Memory networks)
一种特殊的RNN网络,该网络设计出来是为了解决长依赖问题。该网络由 Hochreiter & Schmidhuber (1997)引入,并有许多人对其进行了改进和普及。他们的工作被用来解决了各种各样的问题,直到目前还被广泛应用
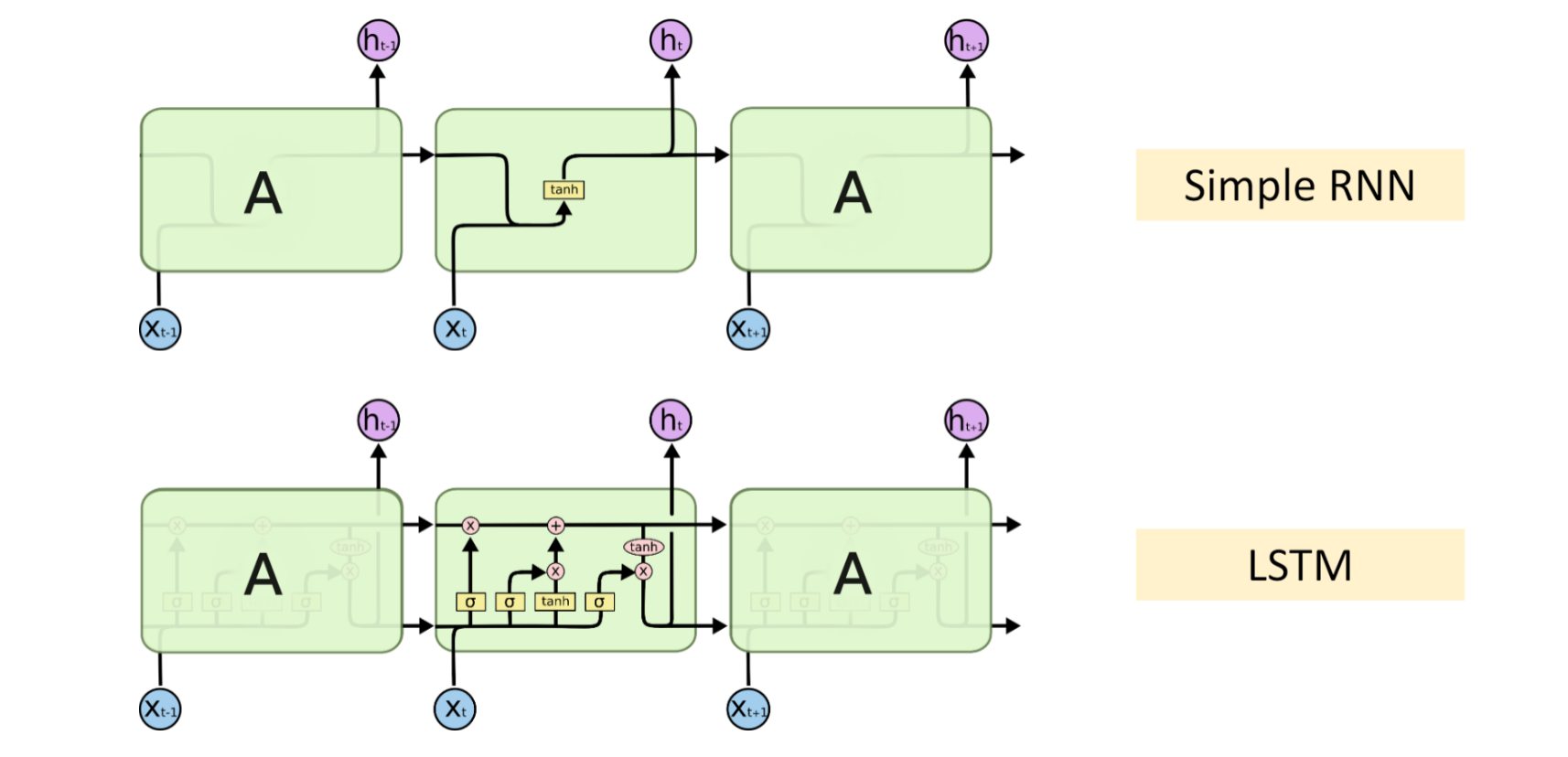
从上图直观的可以看出,如果把RNN这个,传递上个神经网络细胞状态的机制称之为传送带的话,LSTM就拥有一套更为复杂的传送带机制,其涵盖了遗忘,更新记忆等复杂的长序列处理工艺。
展开来讲LSTM的结构,主要是三个部分
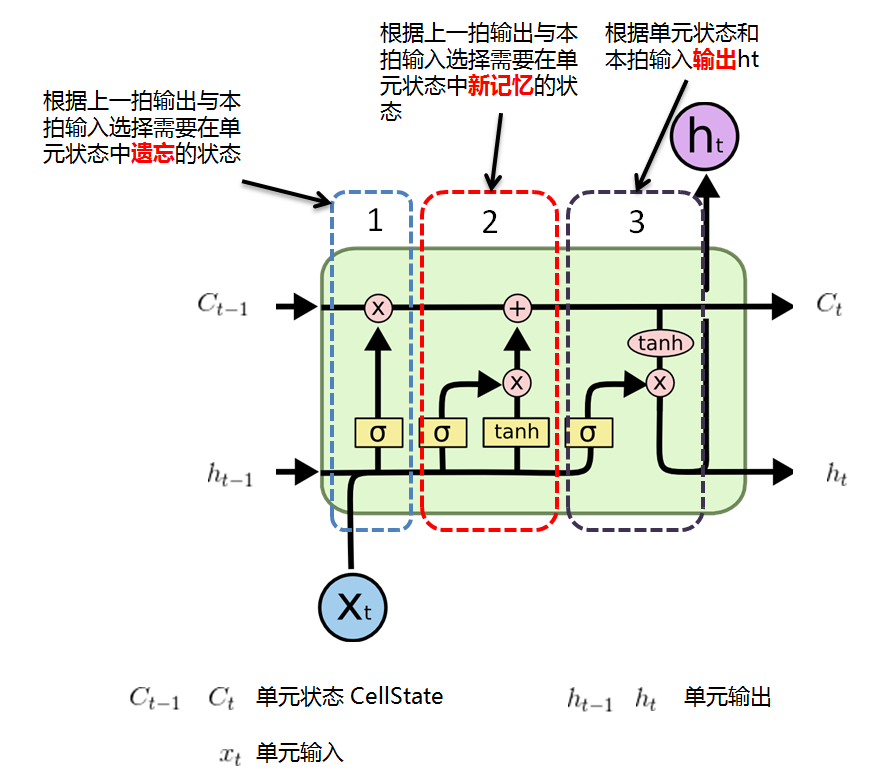
非常非常值得注意的是,这个图有一点反直觉:可以看到有两个传送带,h_t 代表神经网络输出,C_t 代表细胞状态,也就是神经网络的工作状态。虽然我们可以看到该图左上角一个大大的紫色 h_t 的输出,但是,其代表的传送带其实是下面这条!这个图有一个交叉的部分,给它绕上去了,看下图会比较明显。
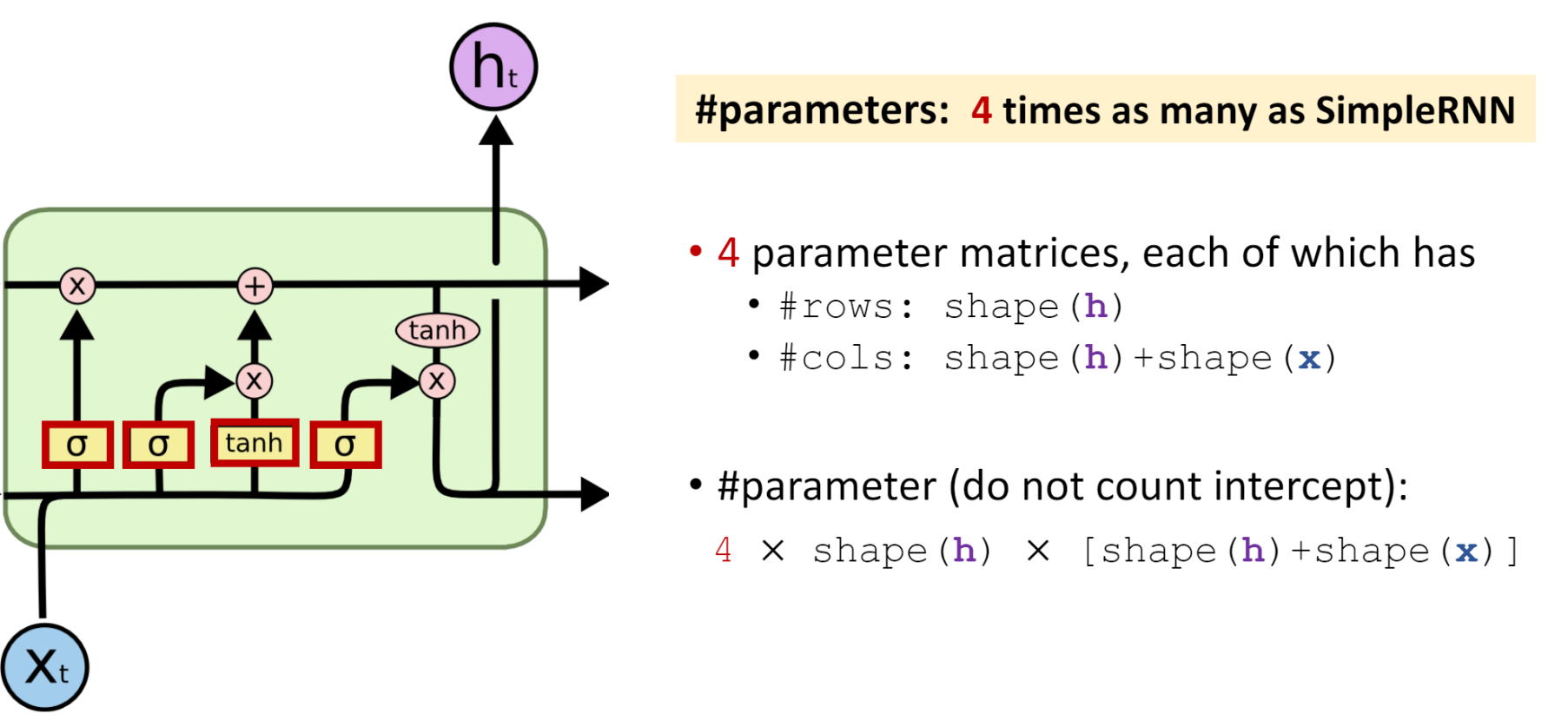
真是夸张的图,吐槽就到这里了。
遗忘门
门结构就略过好了,因为我数学不好,公式这里不讲,提供一些友链供大家学习。
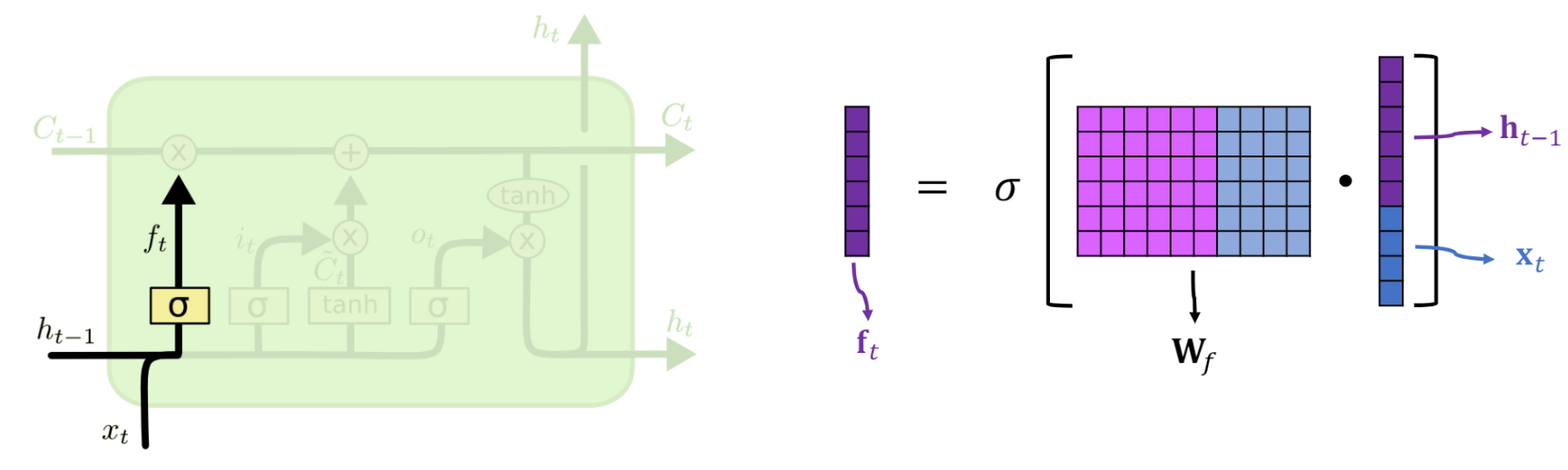
遗忘门就是使用了本次的输入和上次的输出,进行一次交互,然后决定了哪些东西该遗忘,实际作用在了 C_{t-1} 上。
输入门

C_{t-1} 经过遗忘门会丢掉一些东西,那么下一站就可以来到一个输入门,该门决定了需要留下哪些“新记忆”。
输出
最后 C_{t-1} 细胞状态被更新完毕,这时绕一个弯和下方的输入进行正式的计算,输入+神经网络当然会得到一个输出,此输出就是一般意义上的该时间节点神经网络提取到的特征向量。
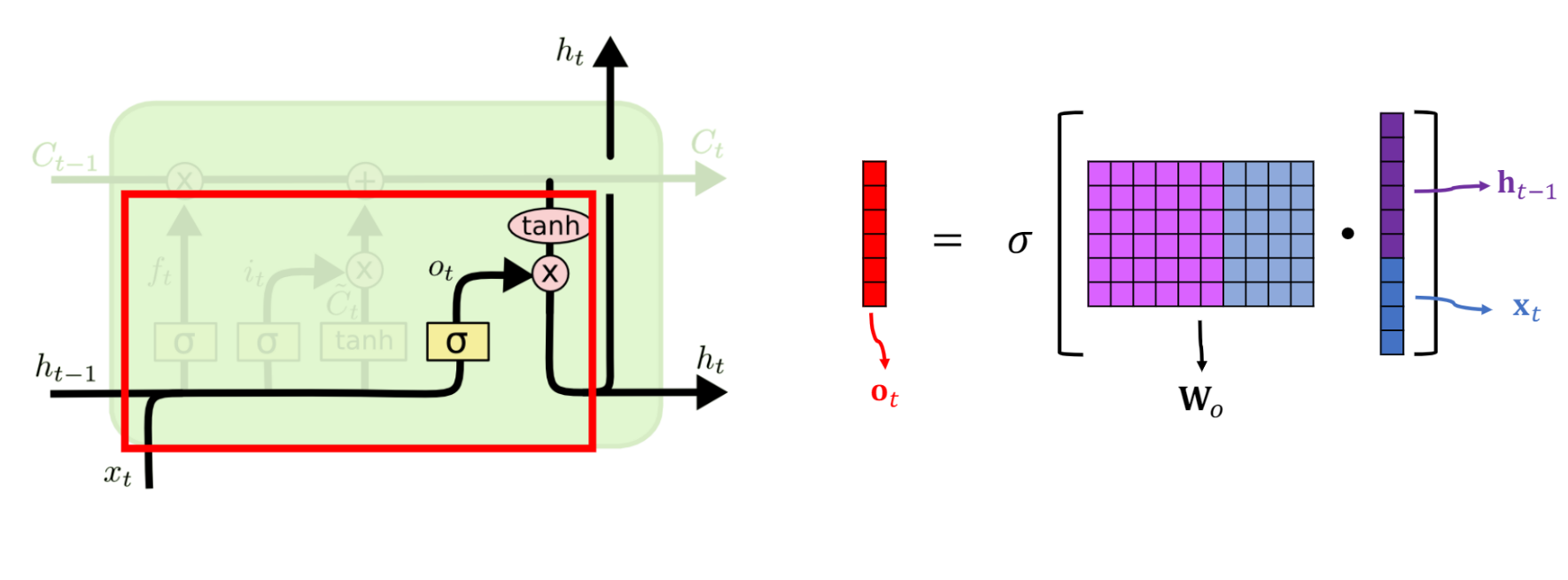
可以看到,输出的 h_t 其实还有一个副本,一个用于输出,一个通过传送带进入下一轮的计算。
总结
上面复杂的机制实际上和Attention就比较像,因为有记忆的筛选机制,因此一些重要的但是久远的信息就可能被保存下来。与上面提到的RNN相比,LSTM看到的【小明超级喜欢Python】可能就如下图所示:

也就是说,更关注于主谓宾等重要信息,因此LSTM在处理短文本上优势较之RNN相当大。
上面的结论是基于网络学习得出的,严谨点的话应该自己码个代码然后整个热力图来看看,时间不是很多,就先挖个坑在这好了。
参考
30、PyTorch LSTM和LSTMP的原理及其手写复现_哔哩哔哩_bilibili # 手撸传播细节,是真大佬,看懂学会很多
动态可视化LSTM_哔哩哔哩_bilibili # 动图很多,另外本文参考的PDF图片等均出于此佬之手,非常感谢!
如何从RNN起步,一步一步通俗理解LSTM_rnn lstm-CSDN博客 # 超级好文,如果不备份估计要被csdn拿去收费了
[文章导入自 http://qzq-go.notion.site/12949a7b4e7580ceab91cb68ec528cec 访问原文获取高清图片]
